oracle-ai-developer-hub
Part 4 — AsyncOracleStore — long-term cross-thread memory
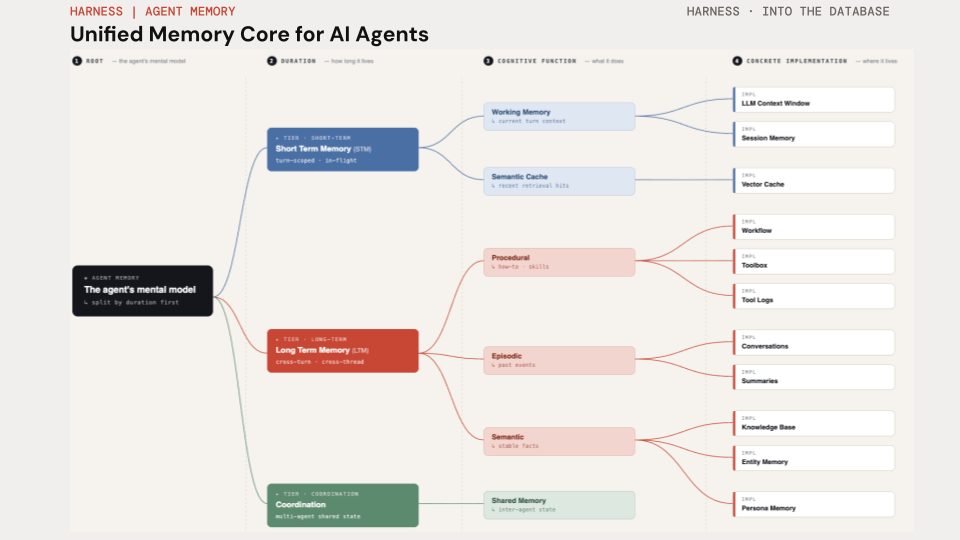
The taxonomy above is the mental model: an agent’s memory splits first by duration, then by cognitive function. This part wires the long-term, cross-thread side — episodic, semantic, and persona memories that outlive any single conversation. Part 5 will pick up the short-term, per-thread side (working memory + session state).
Two kinds of memory
LangGraph distinguishes between two horizons of memory, and they have different storage primitives:
| Horizon | What it remembers | Primitive |
|---|---|---|
| Per-thread, short-term | “what we just said in this conversation” | AsyncOracleSaver (Part 5) |
| Cross-thread, long-term | “facts that outlive any single conversation” | AsyncOracleStore (this part) |
This part wires the long-term one. The store is where you write things like user preferences, org policies, persona facts — anything an agent should know regardless of which thread it’s running on.
Hierarchical namespaces
Unlike OracleVS (where keys are flat IDs and metadata is a dict), an
AsyncOracleStore is hierarchical: every value lives under a tuple
namespace, with a key inside it:
("users", "priya", "memories") / "pref-conservative" → {"note": "…"}
("users", "michael", "memories") / "pref-aggressive" → {"note": "…"}
("orgs", "merch", "policies") / "default-buy-volume" → {"text": "…"}
That layout makes user-scoped, agent-scoped, org-scoped retrieval
straightforward: ask for ("users", user_id, "memories") and you only
see that user’s stuff.
Why use a vector index on a key-value store?
Because we want to retrieve memories by meaning, not by exact key.
The HNSW index on the "note" field means agent_store.asearch(...,
query="…", limit=3) is a vector similarity search inside the chosen
namespace.
agent_store = AsyncOracleStore(
store_conn,
index={
"dims": 384, # ALL_MINILM_L12_V2 = 384-dim
"embed": embeddings, # reuse the in-DB embedder
"fields": ["note"], # embed the "note" field only
"index_type": {"type": "hnsw", "distance_metric": "COSINE"},
},
table_suffix="agent_memory", # ← MUST match the seed script
)
await agent_store.setup()
setup() creates the backing tables if they’re missing, and is
idempotent on re-runs.
Gotcha. The
table_suffixis howAsyncOracleStorefinds its data. The seed script used"agent_memory"; if you write anything else here you’ll create a parallel empty store and the seeded memories will appear invisible.
What’s already in the store
app/scripts/seed_supplychain.py wrote two user memories:
| Namespace | Key | Note (truncated) |
|---|---|---|
("users", "priya", "memories") |
pref-conservative |
“Priya consistently prefers conservative buy volumes …” |
("users", "michael", "memories") |
pref-aggressive |
“Michael chases category leaders …” |
In Part 9 the policy_agent’s get_user_memory(user_id) tool reads
these on demand and returns them to the supervisor for synthesis.
What you’ll build in TODO 3
Construct agent_store and call await agent_store.setup(). The
hard-stop checkpoint reads Priya’s pre-seeded pref-conservative memo
and asserts the note mentions “conservative”. If it doesn’t, your
table_suffix is wrong or the seed step never ran.
Solution
Drop this into the TODO 3 cell, replacing the agent_store = None line
and the trailing # remember to: await agent_store.setup():
from langgraph_oracledb.store.oracle import AsyncOracleStore
agent_store = AsyncOracleStore(
store_conn,
index={
"dims": ONNX_DIMS,
"embed": embeddings,
"fields": ["note"],
"index_type": {"type": "hnsw", "distance_metric": "COSINE"},
},
table_suffix="agent_memory",
)
await agent_store.setup()
Next
→ Part 5 — AsyncOracleSaver — the other memory, scoped to a single thread.