oracle-ai-developer-hub
Part 10 — Supervisor + end-to-end run
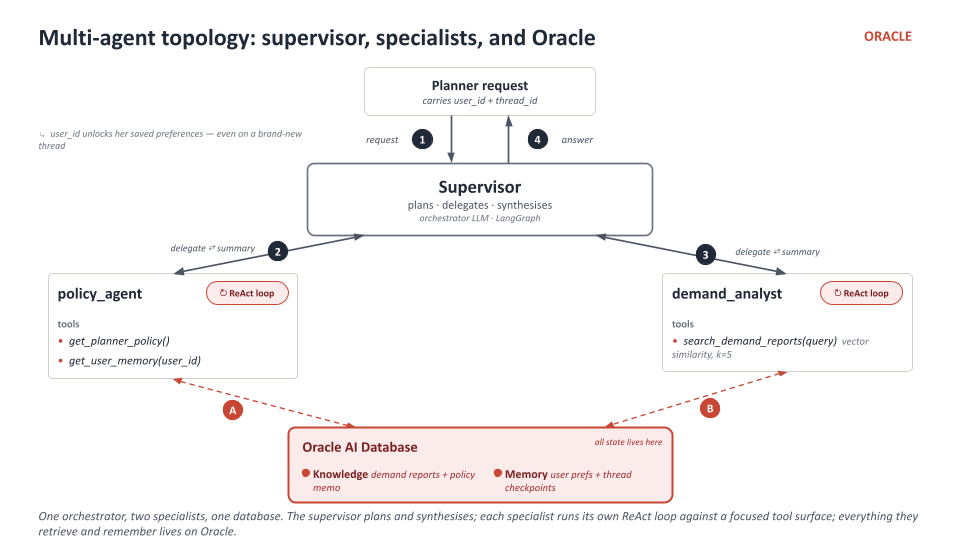
What create_supervisor builds
langgraph_supervisor.create_supervisor(...) builds an orchestrator
agent. Architecturally it’s just another LangGraph agent, but its
“tools” are the specialists you pass in. When the supervisor decides
“I need policy + preferences,” it emits a tool call that hands
control to the policy_agent sub-graph. The specialist runs its own
ReAct loop, returns a single summary message, and control returns to
the supervisor — which can decide to call the other specialist, or to
synthesise the final answer.
┌─────────────────────────────────────┐
│ supervisor │
│ (decides, delegates, synthesises) │
└────────────────┬────────────────────┘
│
┌──────────────────────┼──────────────────────┐
▼ ▼ ▼
policy_agent demand_analyst (synthesis turn)
── tools ── ── tools ── writes the answer
get_planner_policy search_demand_reports
get_user_memory
The supervisor is doing planning + synthesis, never data fetching. The specialists are doing focused retrieval, never end-to-end reasoning. Each agent has one job.
Why decompose at all?
A single ReAct agent could in principle do “search reports → fetch policy → fetch user prefs → synthesise” all by itself. Three reasons not to:
- Context isolation. Each specialist sees only the messages
relevant to its job. The
demand_analystdoesn’t have to wade through policy text; thepolicy_agentdoesn’t read demand reports. Cleaner contexts = better tool selection. - Right tool surface per role. Smaller
tools=[...]lists mean the LLM has fewer ways to misfire. - Reusability. The same
policy_agentcould plug into a returns-management workflow tomorrow without changes.
Compiling with two memory layers
The supervisor only matters if it can both resume a conversation
and recall a planner across conversations. That’s what makes
.compile(...) the most important line in the whole notebook:
supervisor = supervisor_graph.compile(
checkpointer=saver, # per-thread short-term memory (Part 5)
store=agent_store, # cross-thread long-term memory (Part 4)
)
| Memory layer | What it gives you | Without it |
|---|---|---|
checkpointer=saver |
Same thread_id resumes a paused turn |
Every invocation starts fresh |
store=agent_store |
get_user_memory can read across sessions |
Priya’s preferences invisible to a new thread |
The hard-stop checkpoint in this part asserts the final answer
references both: the policy’s 500-unique-IP threshold (from
OracleVS) and Priya’s saved “conservative” preference (from
AsyncOracleStore). If either is missing from the answer, one of
your wires is wrong.
The supervisor’s system prompt
prompt=(
"You are the supply-chain planning supervisor. For any planner request:\n"
"1. Delegate to `policy_agent` for the standing policy + the active planner's user_id memories.\n"
"2. Delegate to `demand_analyst` for historical demand data on the relevant categories.\n"
"3. Synthesise a concise buy recommendation that respects BOTH the policy and the user's "
"saved preferences. Cite the data inline."
)
Notice it tells the supervisor exactly the decomposition order. That keeps token-cost predictable: two specialist calls + one synthesis turn = roughly three LLM round-trips per planner question.
The end-to-end invocation
result = await supervisor.ainvoke(
{"messages": [{"role": "user", "content": NEW_REQUEST}]},
config={"configurable": {"thread_id": "demand-plan-soccer-multiagent"}},
)
final = result["messages"][-1].content
final is the supervisor’s synthesised buy recommendation. The
checkpoint cell prints it and verifies it weaves both Oracle data
sources.
What you’ll build in TODO 9
Everything above. The hard-stop checkpoint demands:
supervisor is not None(you compiled it)finalis non-empty (you invoked + bound the answer)- the answer text mentions the policy threshold (
"500"or"policy") - the answer text mentions Priya or her preference (
"priya"or"conservative")
If the threshold doesn’t appear, the supervisor didn’t call
policy_agent (or the agent didn’t surface the policy). If Priya
doesn’t appear, the get_user_memory tool didn’t fire (or you didn’t
compile with store=agent_store).
Solution
Drop this into the TODO 9 cell, replacing the supervisor_graph = None,
supervisor = None, result = None, and final = "" placeholders:
from langgraph_supervisor import create_supervisor
supervisor_graph = create_supervisor(
[demand_analyst, policy_agent],
model=agent_model,
prompt=(
"You are the supply-chain planning supervisor. For any planner request:\n"
"1. Delegate to `policy_agent` for the standing policy + the active planner's "
"user_id memories.\n"
"2. Delegate to `demand_analyst` for historical demand data on the relevant categories.\n"
"3. Synthesise a concise buy recommendation that respects BOTH the policy and the "
"user's saved preferences. Cite the data inline."
),
)
supervisor = supervisor_graph.compile(
checkpointer=saver,
store=agent_store,
)
print(f"multi-agent supervisor compiled on {LLM_PROVIDER}/{LLM_MODEL}")
NEW_REQUEST = (
"I'm planner with user_id=priya. We're debating how aggressively to stock "
"soccer / football merchandise for the upcoming season. Pull demand intel "
"from comparable SKUs in our history and draft a buy recommendation that "
"respects my preferences and the standing policy."
)
THREAD_ID = "demand-plan-soccer-multiagent"
result = await supervisor.ainvoke(
{"messages": [{"role": "user", "content": NEW_REQUEST}]},
config={"configurable": {"thread_id": THREAD_ID}},
)
final = result["messages"][-1].content
print(final)
Next
→ Part 11 — OracleChatMessageHistory — a standalone primitive for plain chatbots.